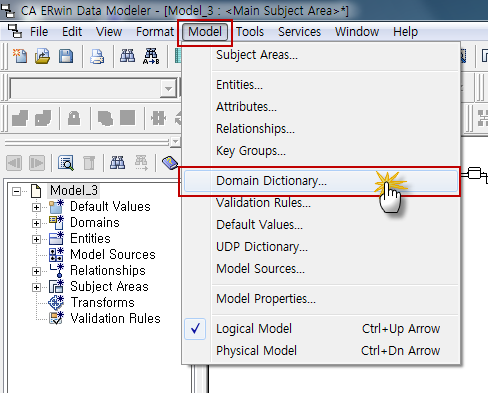
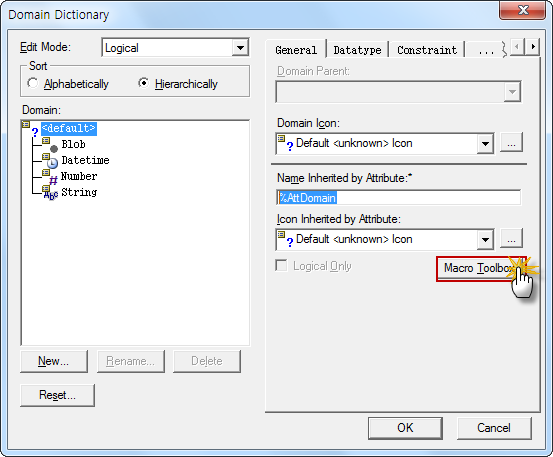
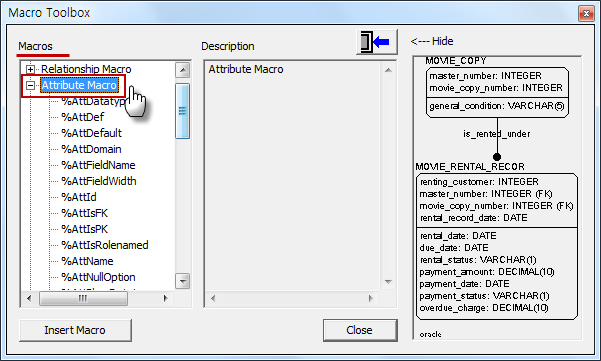
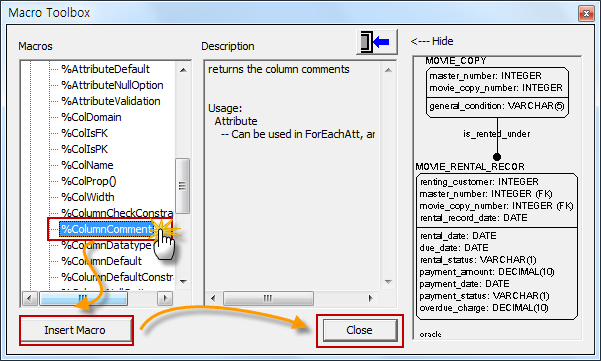
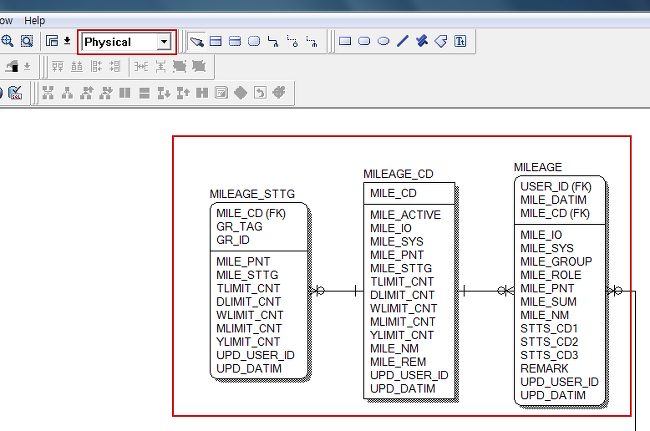
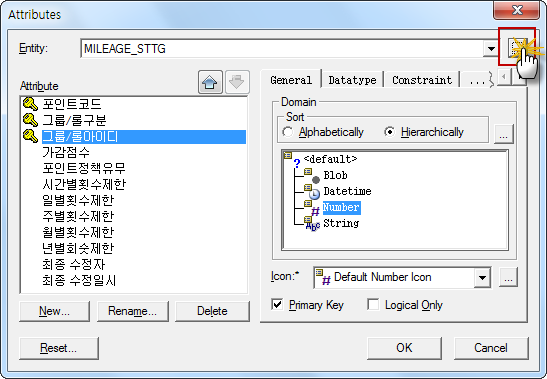
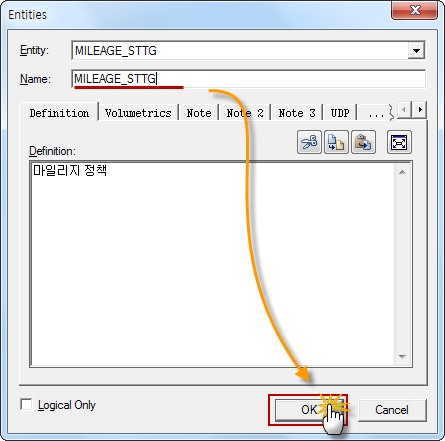
DBeaver 커뮤니티 에디션에서 기본 제공하지 않는 Cassandar 접속 방법
Setting up Cassandra JDBC Driver in DBeaver Community Edition
DBeaver is a widely used cross-platform database management application catered to developers, administrators, and analysts looking for efficient ways to work with their data. It supports many popular databases like MySQL, PostgreSQL, SQL Server, and more.
DBeaver comes in two flavors:
- DBeaver Community Edition - the free and open-source version, offering built-in support for over 80 popular databases and a top-notch SQL editor.
- DBeaver PRO - the commercial version with advanced features for exploring, processing, and managing SQL, NoSQL, and cloud data sources, including a visual query builder, an SQL AI assistant, and many other cutting-edge development tools.
All in all, DBeaver CE is an excellent database management solution. Supporting so many databases out of the box gives you an excellent opportunity to streamline your workflow and manage all of your database connections through a single desktop application, regardless of the underlying database vendor.
However, if you use Apache Cassandra and want to connect to Cassandra using DBeaver, you will immediately discover that the Community Edition doesn't seem to support this use case out of the box. But the good news is that DBeaver can actually access any database that has a compatible JDBC driver.
So in this article, I will show you how to connect to Cassandra with DBeaver using a Cassandra JDBC driver.
Download Cassandra JDBC Driver
| Cassandra JDBC Driver 파일 |
Database vendors typically provide JDBC drivers to enable software engineers to interact with their databases, and DataStax (one of the largest contributors to the open-source Cassandra project) used to distribute the Simba JDBC driver for Apache Cassandra as a free download on their website at https://downloads.datastax.com/#odbc-jdbc-drivers.
For a long time, this driver was the de facto standard JDBC driver for Cassandra. However, at the time of this writing, the Simba JDBC driver is no longer available for download on the DataStax website.
Fortunately, the folks from ING Bank have developed a working alternative by wrapping the DataStax Java Driver for Apache Cassandra into a simple JDBC-compliant API that works perfectly with CQL3.
To download their driver:
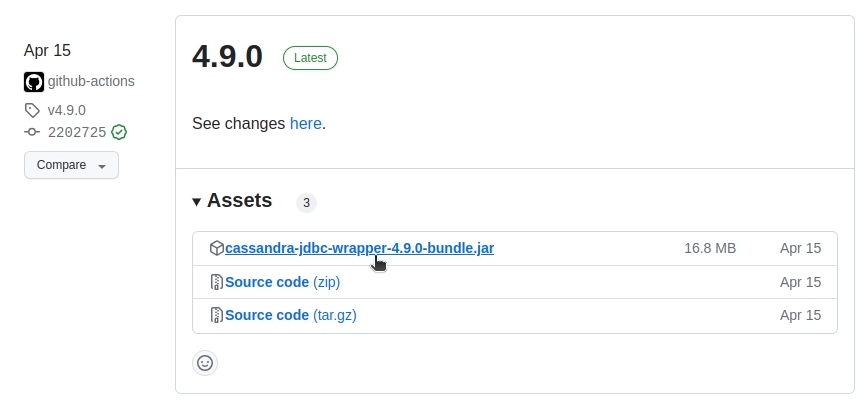
1. Go to https://github.com/ing-bank/cassandra-jdbc-wrapper and navigate to "Releases"
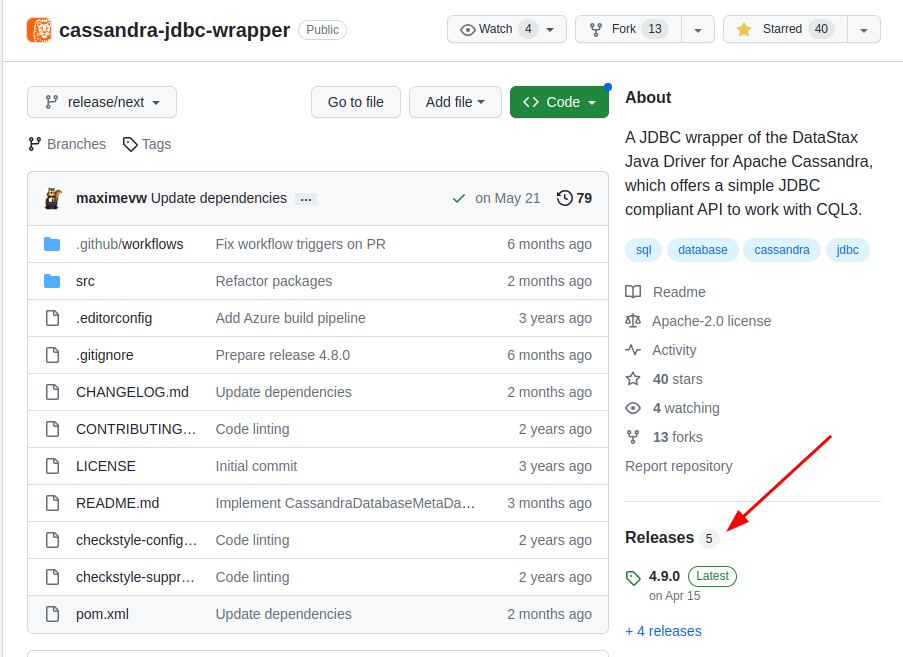
2. Download the cassandra-jdbc-wrapper-4.9.0-bundle.jar file (the latest version of the driver at the time of this writing)
Add Cassandra JDBC Driver to DBeaver
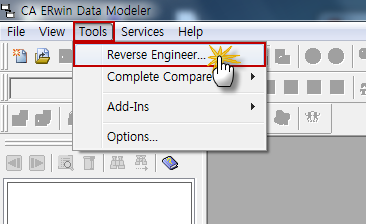
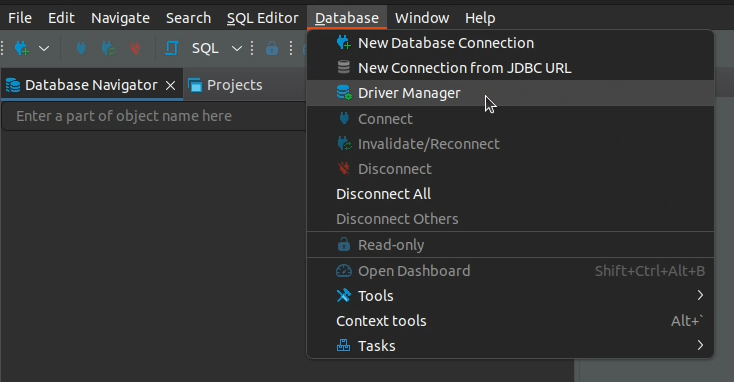
1. Open DBeaver and from the Menu navigate to Database -> Driver Manager.
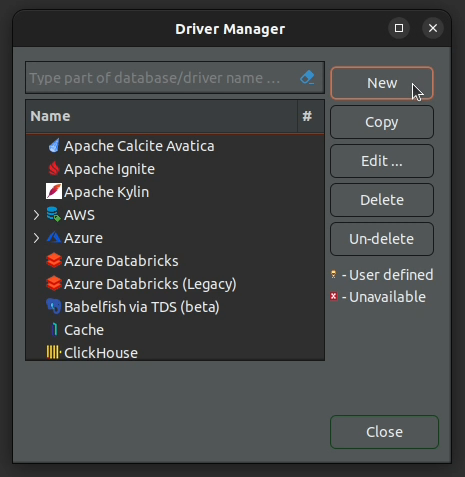
2. Select "New" to define a new Driver.
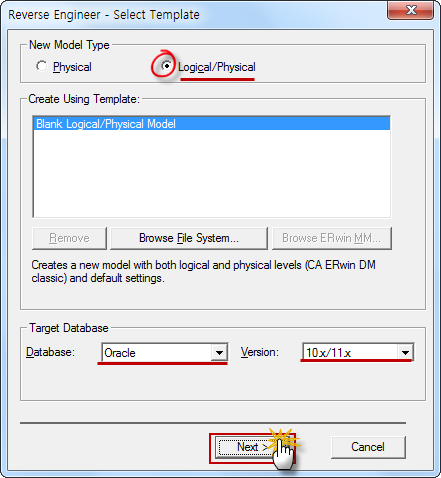
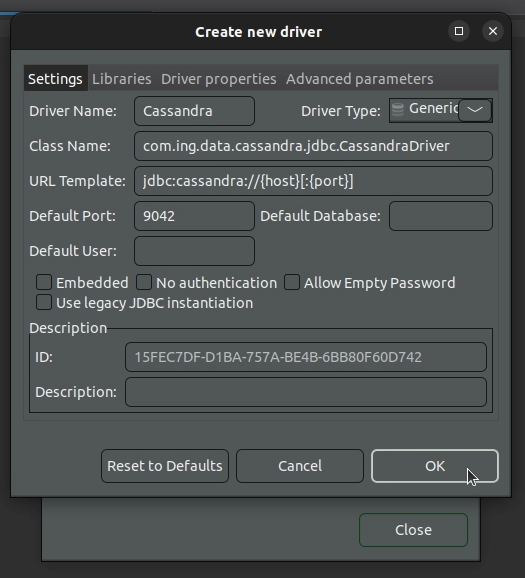
3. Fill in the form for creating a new driver as follows:
Driver Name: Cassandra
Class Name: com.ing.data.cassandra.jdbc.CassandraDriver
URL Template: jdbc:cassandra://{host}[:{port}]
Default Port: 9042
4. Navigate to the Libraries tab and add the JAR file containing the Cassandra JDBC driver that we just downloaded.
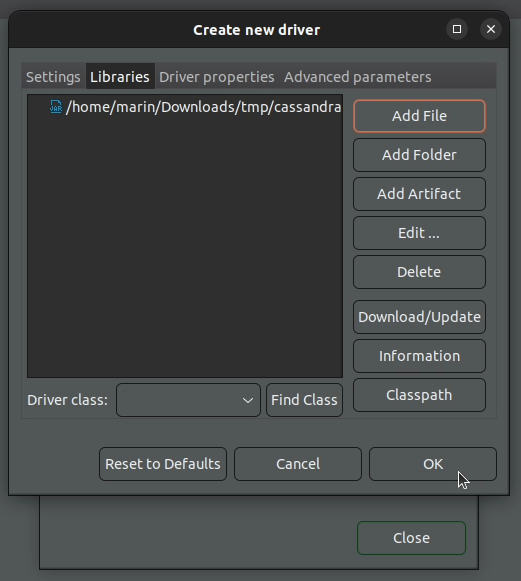
5. Click "OK" and Cassandra should now be listed under the available drivers.
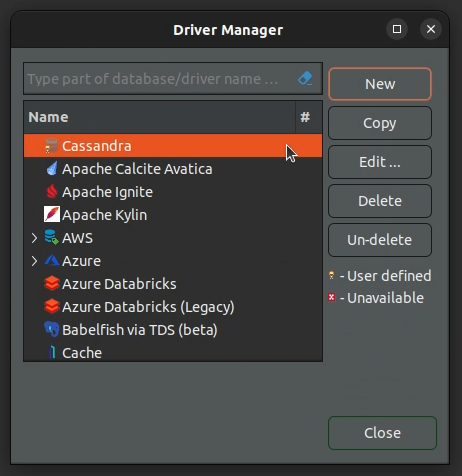
Connect to Cassandra
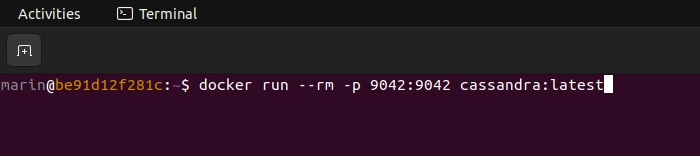
1. Start a local Cassandra instance with Docker.
docker run --rm -p 9042:9042 cassandra:latest
2. Click on "New Database Connection" to create a new connection.
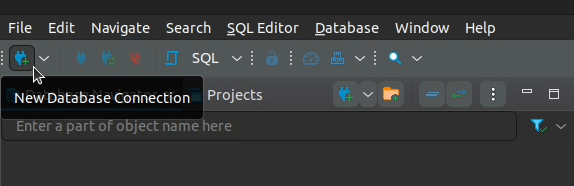
3. Type in "Cassandra" and select the matching database driver that we just created, then click "Next".
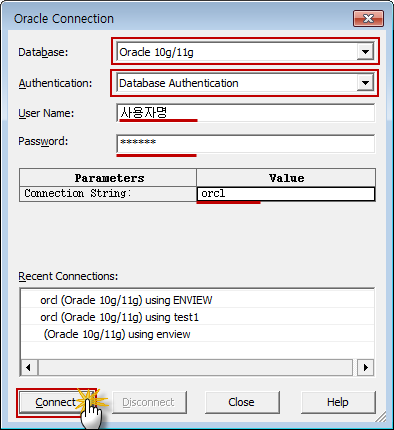
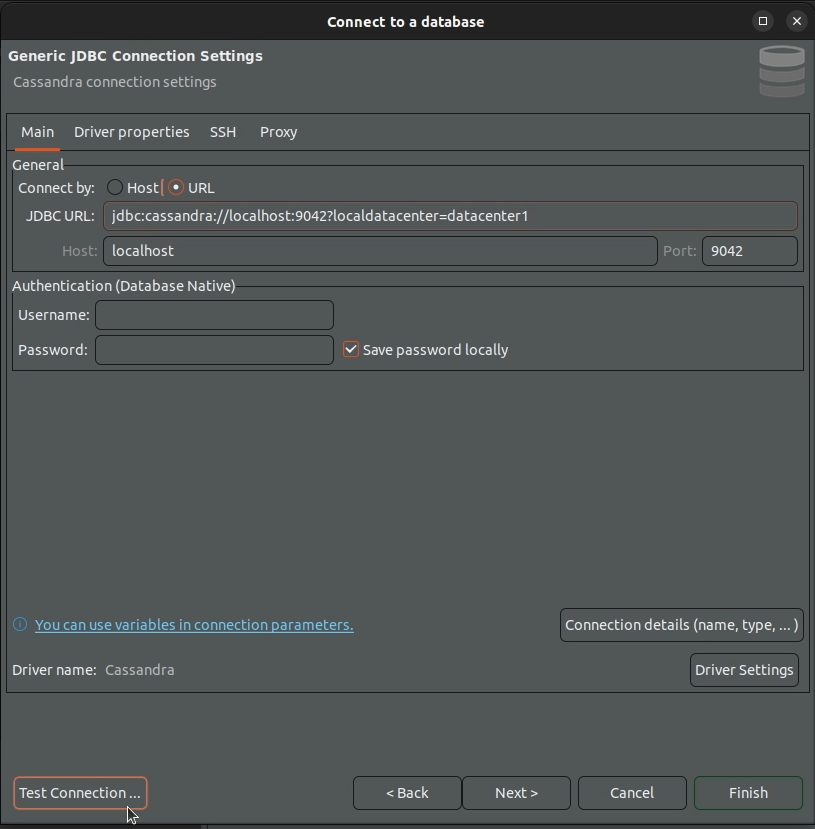
4. Fill in the JDBC connection settings.
Connect by: URL
JDBC URL: jdbc:cassandra://localhost:9042?localdatacenter=datacenter1
The ?localdatacenter part is important (assuming you have started the Cassandra Docker container with the default settings) as without it you wouldn't be able to issue commands against your Cassandra cluster.
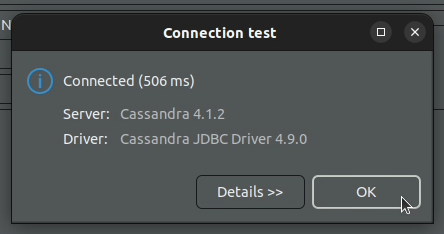
5. Click "Test Connection" and then "OK" when the test is successfull - you should now be able to execute commands against your test cluster.
Execute a Cassandra CQL Query
1. Open a new SQL editor window.
2. Paste the following query in the SQL editor and execute it.
CREATE KEYSPACE testing
WITH REPLICATION = {
'class' : 'SimpleStrategy',
'replication_factor' : 1
};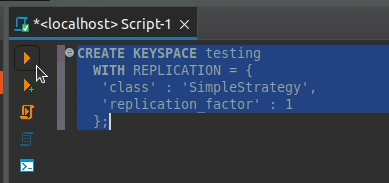
3. You have successfully created a new keyspace named testing in your local Cassandra cluster.
'유틸' 카테고리의 다른 글
| ERwin 모델 쿼리 조회 (0) | 2023.03.09 |
|---|---|
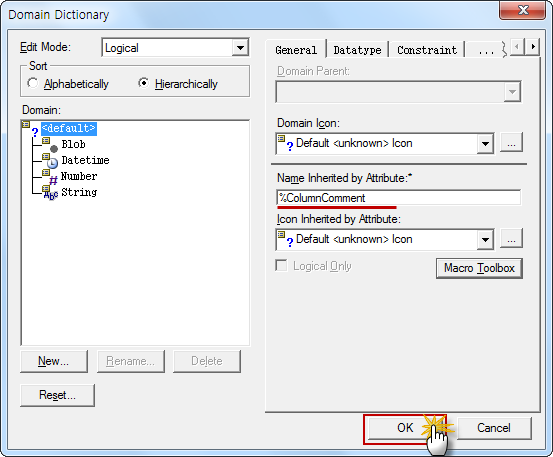
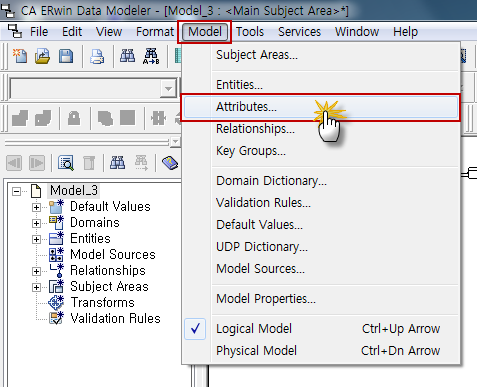
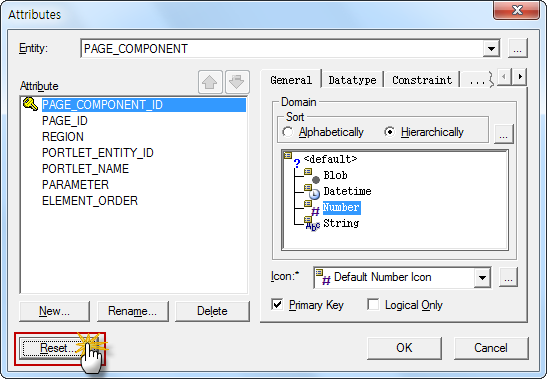
| ERWin 7.3 리버스를 통한 컬럼 Comment 로 Logical 한글명 만들기 (0) | 2023.03.09 |
| log4j 스캐너 - url이용해서 스캔 (0) | 2022.02.09 |
| JDBC 드라이버 모음 - 알티베이스, 큐브리드 (0) | 2022.02.08 |
| 윈도우 환경 소나큐브(Sonarqube) sonar-scanner 설치 (0) | 2022.01.25 |